Performance
On this page
Besides flexibility, performance is of high importance of Comunica. That is why we keep a close eye to it through continuous performance tracking and large scale benchmarks.
Continuous performance tracking
To keep track of the evolution of Comunica's performance, we enable continuous performance tracking into our continuous integration. For various benchmarks, we can observe the evolution of execution times across our commit history. This allows us to easily identify which changes have a positive or negative impact on performance.
For considering the performance for different aspects, we have included the following benchmarks:
- WatDiv (in-memory)
- WatDiv (TPF)
- Berlin SPARQL Benchmark (in-memory)
- Berlin SPARQL Benchmark (TPF)
- Custom web queries: manually crafted queries to test for specific edge cases over the live Web
This allows us to inspect performance as follows:
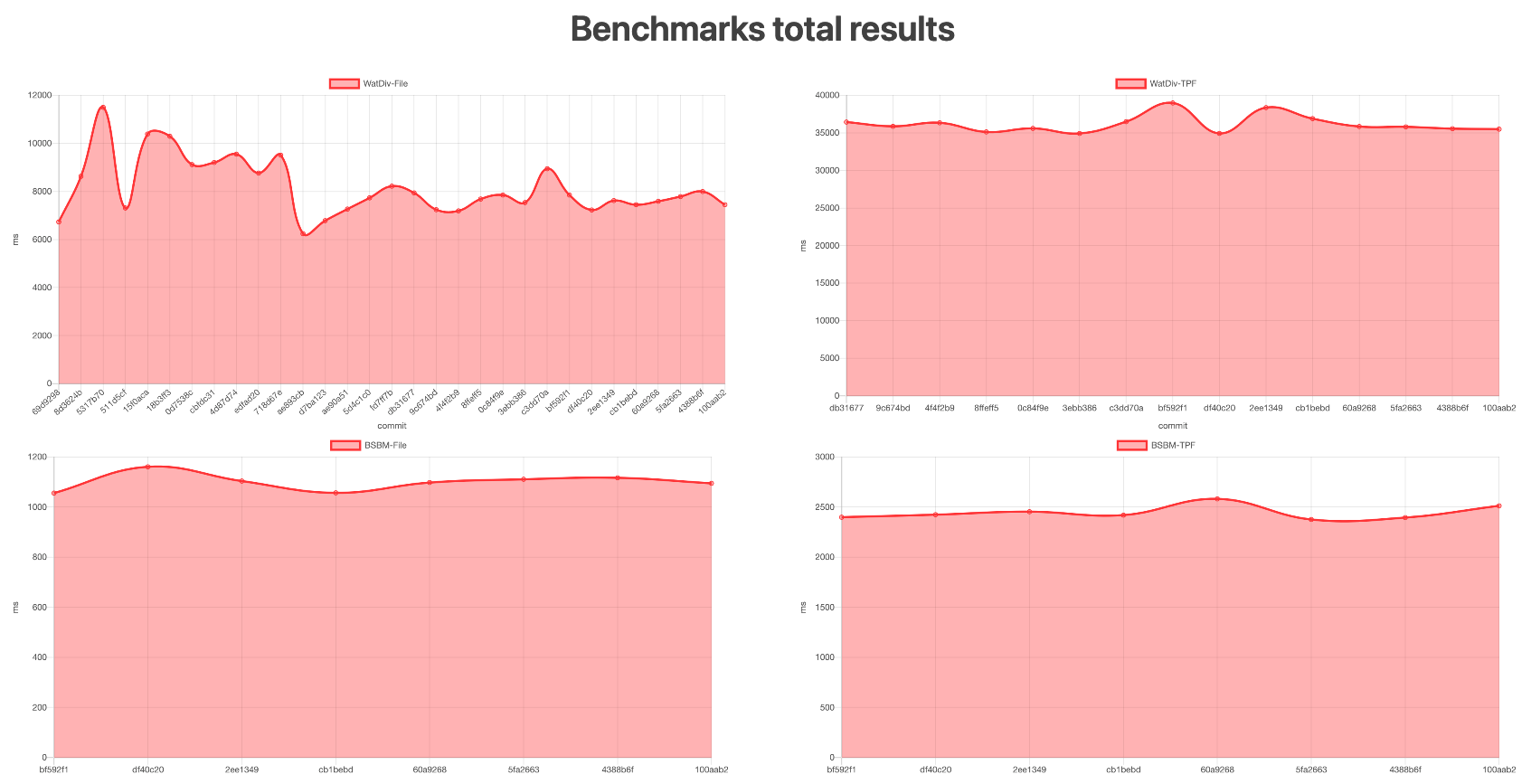
Fluctuations in the graph are mainly caused by confounding variables in the GitHub Actions environment, such as running on different hardware and runner versions.
These results can be inspected in more close detail together with execution times per query separately.
Centralized performance
Despite Comunica focusing on query execution over decentralized Knowledge Graphs, it's still possible to use Comunica to query over a single centralized Knowledge Graph. While we discourage this usage if you want to query over huge Knowledge Graph where performance is highly critical, you can still get decent levels of performance compared to state-of-the-art engines, as can be seen when running the Berlin SPARQL benchmark and the WatDiv benchmark.
The following engines were compared:
- Comunica Memory (
@comunica/query-sparqlv4.2.0) using in-memory triple store. - Comunica HDT (
@comunica/query-sparql-hdtv4.0.2) using an HDT-based triple store. - Jena Fuseki (v4.8.0): A Java-based engine.
- Blazegraph (v2.1.5): A Java-based engine.
- GraphDB (v10.6.4): A Java-based engine.
- Virtuoso (v7.2.14): An engine that translates SPARQL queries to SQL.
- Oxigraph (v0.4.9): A Rust-based engine.
- QLever (22 February 2025): A C++-based engine.
All experiments were executed on a 64-bit Ubuntu 14.04 machine with 128 GB of memory and a 24-core 2.40 GHz CPU, and are fully reproducible. All experiments were preceded with a warmup of five runs, and all execution times were averaged over ten runs. These experiments were last executed in February 2025.
A more detailed write-up of these experiments can be found here.
BSBM Results
Below, execution times can be found for the Berlin SPARQL benchmark for an increasing dataset scale.
QLever is not included in this benchmark, since the BSBM benchmark runner requests results as SPARQL/XML,
which was not supported by QLever at the time of writing.
Query 6 is not included, because it was removed from the benchmark.
Query 7 is also not included, as it uses the DESCRIBE keyword, which is not normatively defined in the SPARQL specification, so different engines can have different implementations, leading to performance differences.
For the largest BSBM scale that was run (100K), Comunica-Memory is not included due to memory issues.






WatDiv Results
Below, execution times can be found for the WatDiv benchmark for an increasing dataset scale. For the largest WatDiv scale that was run (100K), Comunica-Memory is not included due to memory issues.




